Appearance
2024年3月中旬再读x3
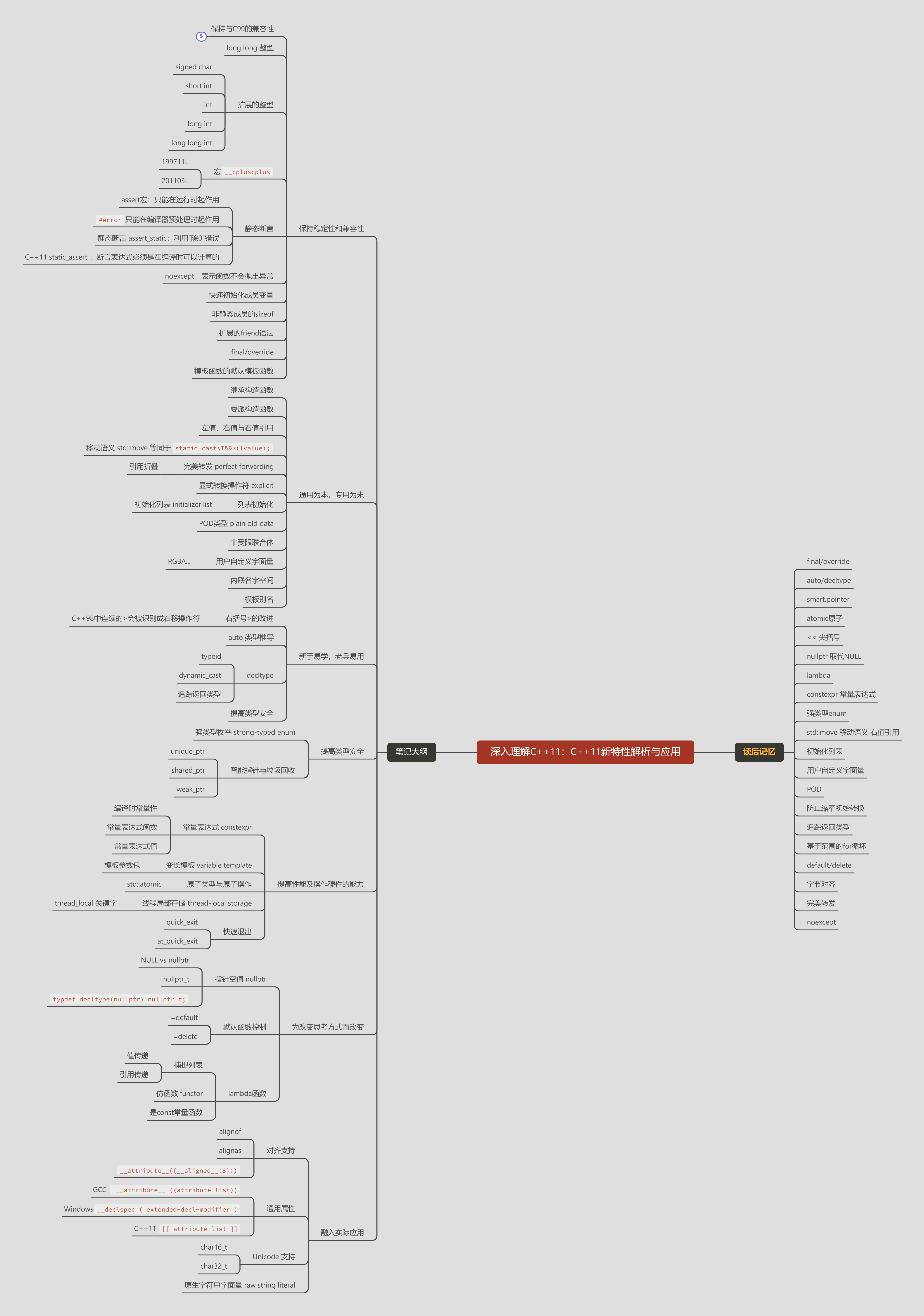
阅读目标:
C++98 to C++11
新特性,为了解决问题什么而添加了什么特性?
丢弃了C++98的那些劣势
新特性 罗列和使用熟悉
关于C++的有用资源渠道不限于:
C++官方网站、标准
关于C++的提案、变化趋势
C++ 有关的书籍、网页资源
快读后的感受和理解记忆:
final/override
auto/decltype
smart.pointer
atomic原子
<< 尖括号
nullptr 取代NULL
lambda
constexpr 常量表达式
强类型enum
std::move 移动语义 右值引用
初始化列表
用户自定义字面量
POD
防止缩窄初始转换
追踪返回类型
基于范围的for循坏
default/delete
字节对齐
完美转发
noexcept
第1章
C++0x是WG21计划取代C++98/03的新标准代号。这个代号还是在2003年的时候取的。
C语言标准委员会(C committee)WG14也几乎在同时开始致力于取代C99标准。
那么C++11相对于C++98/03有哪些显著的增强呢?事实上,这包括以下几点:
通过内存模型、线程、原子操作等来支持本地并行编程(Native Concurrency)。
通过统一初始化表达式、auto、declytype、移动语义等来统一对泛型编程的支持。
通过constexpr、POD(概念)等更好地支持系统编程。
通过内联命名空间、继承构造函数和右值引用等,以更好地支持库的构建。
C++11的新关键字如下:
alignas
alignof decltype
auto(重新定义)
static_assert
using(重新定义)
noexcept
export(弃用,不过未来可能留作他用)
nullptr
constexpr
thread_local
虽然设计C++11的目的是为了要取代C++98/03,不过相比于C++03标准,C++11则带来了数量可观的变化,这包括了约140个新特性,以及对C++03标准中约600个缺陷的修正。
在C中,用static修饰的变量或函数,主要用来说明这个变量或函数只能在本文件代码块中访问,而文件外部的代码无权访问。并且static修饰的变量存放在段存储区。
在文件作用域中声明的inline函数默认为static类型
没有数组的引用,因为数组不是单个元素,所以无法给若干元素定义一个别名。
数组名a可以作为数组的首地址,而&a是数组的指针
第2章 保证稳定性和兼容性
保持与C99兼容
C99 标准中的预定义标识符__func__,功能是返回所在函数的名字。
在 C/C++标准中,#pragma 是一条预处理的指令(preprocessor directive),简单来说#pragma是用来向编译器传达语言标准以外的一些信息。比如:
cpp
#pragma once在C++11中,标准定义了与预处理指令#pragma功能相同的操作符_Pragma:
cpp
_Pragma (字符串字面量)变长参数的宏定义以及__VA_ARGS__
在 C99 标准中,程序员可以使用变长参数的宏定义。变长参数的宏定义是指在宏定义中参数列表的最后一个参数为省略号,而预定义__VA_ARGS__则可以在宏定义的实现部分替换省略号所代表的字符串。
宽窄字符串的连接
在之前的C++标准中,将在字符串(char)转换为宽字符串(wchar_t)是未定义的行为。而在C++11标准中,在将窄字符串和宽字符串进行连接时,支持C++11标准的编译器会将窄字符串转换成宽字符串,然后再与宽字符串进行连接。
long long 整型
相对于C++98标准,C++11整型最大改变就是多了long long。long long 整型有两种:long long和unsigned long long。在C++11中,标准要求long long整型可以在不同平台上有不同的长度,但至少有64位。
扩展的整型
在C++11中一共只定义了以下5种标准的有符号类型:
- signed char
- short int
- int
- long int
- long long int
宏__cplusplus
在C++03标准中,__cplusplus被预定义为199711L,在C++11标准中,宏__cplusplus被预定义为201103L。
cpp
#if __cplusplus < 201103L
#error "should use C++11 implementation"
#endif静态断言
断言:运行时与预处理时
在C++中,标准在<cassert>或<assert.h>头文件中为程序员提供了assert宏,用于在运行时进行断言。在C++中,程序员也可以定义宏NDEBUG来禁用assert宏。
静态断言与static_assert
断言assert宏只有在程序运行时才能起作用,而#error只能在编译器预处理时才起作用。
cpp
#define assert_static(e) \
do { \
enum { assert_static__ = 1/(e) }; \
} while (0)static_assert使用起来非常简单,它接收两个参数,一个是断言表达式,这个表达式通常需要返回一个bool值;一个则是警告信息,它通常也就是一段字符串。
static_assert的断言表达式的结果必须是在编译时期可以计算的表达式,即必须是常量表达式。
noexcept修饰符与noexcept操作符
noexcept形如其名地,表示其修饰的函数不会抛出异常。在C++11中如果noexcept修饰的函数抛出了异常,编译器可以选择直接调用std::terminate()函数来终止程序的运行。 noexcept作为一个操作符时,通常可以用于模板。
cpp
template <class T>
void fun() noexcept(noexcept(T())) {}C++11默认将delete函数设置成noexcept,就可以提高应用程序的安全性。
快速初始化成员变量
在C++98中,支持了在类声明中使用等号“=”加初始值的方式来初始化类中的静态成员变量。这种声明方式我们也称之为“就地”声明。不过,C++98对类中就地声明的要求非常高。如果静态成员不满足常量性,则不可以就地声明,而且即使常量的静态成员也只能时整型或者枚举型才能就地初始化。
在C++11中,标准还允许使用等号=或者花括号{}进行就地的非静态成员变量初始化。
非静态成员的sizeof
从C语言被发明开始,sizeof就是一个运算符。在C++98中,对非静态成员使用sizeof是不能够通过编译的。
cpp
// C++98
sizeof(((People*)0)->hand);
// C++11
sizeof(People::hand)扩展的friend语法
在C++11中,声明一个类为另外一个类的友元时,不再需要使用class关键字。
final/override控制
final关键字的作用是使派生类不可覆盖它所修饰的虚函数。虚函数描述符override,如果派生类在虚函数声明时使用了override描述符,那么该函数必须重载其基类中的同名函数,否则代码将无法通过编译。
final/override也可以定义为正常变量名,只有在其出现在函数后时才是能够控制继承/派生的关键字。
函数模板的默认模板参数
函数模板在C++98中与类模板一起被引入,不过在模板类声明的时候,标准允许其有默认模板参数。默认的模板参数的作用好比函数的默认形参。然而由于种种原因,C++98标准却不支持函数模板的默认模板参数。
函数模板的默认形参不是模板参数推导的依据。函数模板参数的选择,总是由函数的实参推导而来的,这点读者在使用中应当注意。
外部模板 显式的实例化与外部模板的声明
局部和匿名类型作模板实参
在C++98中,标准对模板实参的类型还有一些限制。具体地讲,局部的类型和匿名的类型在C++98中都不能做模板类的实参。在C/C++中,即使是匿名类型的声明,也需要独立的表达式语句。
第3章 通用为本,专用为末
继承构造函数
委派构造函数
在C++11中,所谓委派构造,就是指委派函数将构造的任务委派给了目标构造函数来完成这样一种类构造的方式。
在C++中,构造函数不能同时“委派”和使用初始化列表,所以如果委派构造函数要给变量赋初值,初始化代码必须放在函数体中。
右值引用:移动语义和完美转发 指针成员与拷贝构造 浅拷贝(shollow copy) 深拷贝(deep copy) “移动语义”(move semantics) 左值、右值与右值引用 一个最为典型的判别方法就是,在赋值表达式中,出现在等号左边的就是“左值”,而在等号右边的,则称为“右值”。
可以取地址、有名字的就是左值;不能取地址、没有名字的就是右值。
右值由两个概念构成:将亡值(xvalue,eXpiring value),纯右值(prvalue,pure value)
左值引用是具名变量值的别名,而右值引用则是不具名(匿名)变量的别名。
在C++11中,标准库在<utility>中提供了一个有用的函数std::move
std::move并不能移动任何东西,它唯一的功能是将一个左值强制转化为右值引用,继而我们可以通过右值引用使用该值,以用于移动语义。
从实现上看,std::move基本等同于一个类型转换:
cpp
static_cast<T&&>(lvalue);完美转发
C++11是通过引入一条所谓“引用折叠”(reference collapsing)的新语言规则,并结合新的模板推导规则来完成完美转发。
cpp
typedef const int T;
typedef T& TR;
TR& v = 1; // 该声明在C++98中会导致编译错误| TR的类型定义 | 声明v的类型 | v的实际类型 |
|---|---|---|
| T& | TR | A& |
| T& | TR& | A& |
| T& | TR&& | A& |
| T&& | TR | A&& |
| T&& | TR& | A& |
| T&& | TR&& | A&& |
因为一旦定义中出现了左值引用,引用折叠总是优先将其折叠为左值引用。
当转转发函数的实参是类型X的一个左值引用,那么模板参数被推导为X&类型,而转发函数的实参是类型X的一个右值引用的话,那么模板的参数被推导为X&&类型.
模板对类型的推导规则就比较简单,当转发函数的实参是类型X的一个左值引用,那么模板参数被推导为X&类型,而转发函数的实参是类型X的一个右值引用的话,那么模板的参数被推导为X&&类型。
完美转发的一个作用就是做包装函数,这是一个很方便的功能。
make_pair、make_unique等在C++11都通过完美转发实现了
显式转换操作符
explicit关键字作用于类型转换操作符上,意味着只有在直接构造目标类型或显式类型转换的时候可以使用该类型
列表初始化
初始化列表 initializer list 在C++98中,标准允许使用花括号“{}”对数组元素进行统一的集合(列表)初始值设定,如:
cpp
int arr[5] = {0};
int arr[] = {1, 2, 3, 4} ;等号 “=”加上赋值表达式,比如 int a = 3+4;
等号“=”加上花括号式的初始化列表,比如int a = {3+4};
圆括号式的表达式列表(expression-list),比如int a(3+4);
花括号式的初始化列表,比如 int a{3+4};
标准模板库中容器对初始化列表的支持源自<initializer_list>这个头文件中initialize_list类模板的支持。
只要#include了<initializer_list>头文件,并且声明一个以initialize_list<T>模板类为参数的构造函数,同样可以使得自定义的类使用列表初始化
防止类型收窄
使用列表初始化还有一个最大优势是可以防止类型收窄(narrowing)。类型收窄一般是指一些可以使得数据变化或者精度丢失的隐式类型转换。
在C++11中,使用初始化列表进行初始化的数据编译器是会检查其是否发生类型收窄的。
在C++11中,列表初始化是唯一一种可以防止类型收窄的初始化方式。这也是列表初始化区别于其他初始化方式的地方。
POD类型 plain old data C++11将POD划分为两个基本概念的合集,即:平凡的(trivial)和标准布局的(standard layout)。
cpp
template <typename T> struct std::is_trivial;
// std::is_trivial<int>::value;cpp
template <typename T> struct std::is_pod;非受限联合体
在C/C++中,联合体(Union)是一种构造类型的数据结构。
用户自定义字面量
literal
内联名字空间
在C++11中,标准引入了一个新特性,叫做“内联的名字空间”。通过关键字“inline namespace”就可以声明一个内联的名字空间
模板的别名
cpp
template<typename T> using MapString = std::map<T, char*>;
MapString<int> numberedString;一般化的SFINEA规则 在C++模板中,有一条著名的规则,SFINEA-Substitution failure is not an error,即“匹配失败不是错误”
第4章 新手易学,老兵易用
auto、decltype、range-based-for
右尖括号>的改进
在C++98中,有一条需要程序员规避的规则:如果在实例化模板的时候出现了连续的两个右尖括号>,那么它们之间需要一个空格来进行分隔,以避免发生编译时的错误。
cpp
template <int i> class X{};
template <class T> class Y{};
Y<X<1> > x1; // 编译成功
Y<X<2>> x2; // 编译失败C++98同样会将>>优先解析为右移。
auto类型推导
volatile和const代表了变量的两种不同的属性:易失的和常量的。在C++标准中,它们常常被一起叫作cv限制符(cv-qualifier)
decltype
C++98对动态类型支持就是C++中的运行时类型识别(RTTI)。RTTI的机制是为每个类型产生一个type_info类型的数据,程序员可以在程序中使用typeid随时查询一个变量的类型,typeid就会返回变量相应的type_info数据。在C++11中,又增加了hash_code这个成员函数,返回该类型唯一的哈希值,以供程序员对变量的类型随时进行比较。
除了typeid外,RTTI还包括了C++中的dynamic_cast等特性
decltype的类型推导并不是像auto一样是从变量声明的初始化表达式获得变量的类型,decltype总是以一个普通的表达式为参数,返回该表达式的类型。
比较典型的就是decltype与typdef/using的合用
cpp
using size_t = decltype(sizeof(0));
using ptrdiff_t = decltype((int*)0 - (int*)0);
using nullptr_t = decltype(nullptr);事实上,decltype一个最大的用途就是用在追踪返回类型的函数中
但是程序员必须要注意的是,decltype只能接受表达式做参数,像函数名做参数的表达式decltype(hash)是无法通过编译的。
基于decltype的模板类result_of,其作用是推导函数的返回类型
cpp
#include <type_traits>
using namespace std;
typedef double (*func)();
int main() {
result_of<func()>::type f; // 由func()推导出其结果类型
return 0;
}
// result_of
template<class>
struct result_of;
template<class F, class... ArgTypes>
struct result_of<F(ArgTypes...)>
{
typedef decltype(
std::declval<F>()(std::declval<ArgTypes>()...)
) type;
};与auto类型推导时不能“带走”cv限制符不同,decltype是能够“带走”表达式的cv限制符的。不过,如果对象的定义中有const或volatile限制符,使用decltype进行推导时,其成员不会继承const或volatile限制符
追踪返回类型
cpp
template<typename T1, typename T2>
auto Sum(T1 & t1, T2 & t2) -> decltype(t1 + t2){
return t1 + t2;
}第5章 提高类型安全
strong-typed enum 、 smart pointer
强类型枚举
非强类型作用域,允许隐式转换为整型,占用存储空间及符号性不确定,都是枚举类的缺点。针对这些缺点,新标准C++11引入了一种新的枚举类型,即“枚举类”,又称“强类型枚举” (strong-typed enum)。
强作用域,强类型枚举成员的名称不会被输出到其父作用域空间。
转换限制,强类型枚举成员的值不可以与整型隐式地相互转换。
可以指定底层类型。强类型枚举默认的底层类型为int,但也可以显式地指定底层类型,具体方法为在枚举名称后面加上“:type”,其中type可以是除wchar_t以外的任何整型。
堆内存管理:智能指针与垃圾回收
显式内存管理
野指针wild pointer:一些内存单元已被释放,之前指向它的指针还在使用。
重新释放double free: 程序试图释放已经被释放过的内存单元,或者释放已经被重新分配过的内存单元。
内存泄漏 memory leak: 不再需要使用的内存单元没有释放就会导致内存泄漏。
C++11的智能指针
unique_ptr、shared_ptr、weak_ptr
weak_ptr的使用更为复杂一点,它可以指向shared_ptr指针指向的对象内存,却并不拥有该内存。而使用weak_ptr成员lock,则可返回其指向内存的一个shared_ptr对象,且在所指对象内存已经无效时,返回指针空值
只有shared_ptr参与了引用计数,而weak_ptr没有影响其指向的内存的引用计数
垃圾回收:
- 基于引用计数(reference couting garbage collector)的垃圾回收器
- 基于跟踪处理(tracing garbage collector)的垃圾回收器,基本方法式长生跟踪对象的关系图,然后进行垃圾回收。
- 标记-清除 mark-sweep
- 标记-整理 mark-compact
- 标记-拷贝 mark-copy
第6章 提高性能及操作硬件的能力
constexpr、atomic、边长模板、quick_exit
常量表达式
运行时常量性与编译时常量性
常量表示该值不可修改,通常是通过const关键字来修饰的。大多数情况下,const描述的都是一些“运行时常量性”的概念,即具有运行时数据的不可更改性。C++11中对编译时期常量的回答是constexpr,即常量表达式(constant expression)。
常量表达式函数 通常我们可以在函数返回类型前加入关键字constexpr来使其成为常量表达式函数:
- 函数体只有单一的return返回语句
- 函数必须返回值(不能是void函数)
- 在使用前必须已有定义
- return返回语句表达式中不能使用非常量表达式的函数、全局数据,且必须是一个常量表达式
常量表达式值 constant-expression-value
常量表达式值必须被一个常量表达式赋值,而跟常量表达式函数一样,常量表达式值在使用前必须被初始化。C++11标准中,constexpr关键字是不能用于修饰自定义类型的定义的。
变长模板
变长函数和变长的函数模板
cpp
template <typename... Elements> class tuple;在C++11中,Elements被称作是一个“模板参数包”(template parameter pack)
一个模板参数包在模板推导时会被认为是模板的单个参数(虽然实际上它将会打包任意数量的实参)。为了使用模板参数包,我们总是需要将其解包(unpack)。在C++11中,这通常是通过一个名为包扩展(pack expansion)的表达式来完成。
cpp
template<typename... A> class Template: private B<A...>{};cpp
template <typename... Elements> class tuple; // 变长模板的声明
template<typename Head, typename... Tail> // 递归的偏特化定义
class tuple<Head, Tail...> : private tuple<Tail...> {
Head head;
};
template<> class tuple<> {}; // 边界条件C++11中可以展开参数包的地方:
- 表达式
- 初始化列表
- 基类描述列表
- 类成员初始化列表
- 模板参数列表
- 通用属性列表
- lambda函数的捕捉列表
原子类型与原子操作
cpp
std::atomic<T> t;原子类型只能从其模板参数类型中进行构造,标准不允许原子类型进行拷贝构造、移动构造,以及使用operator=等,以防止发生意外。
事实上,atomic模板类的拷贝构造函数、移动构造函数、operator=等总是默认被删除的。
相比于其他的atomic类型,atomic_flag是无锁的(lock-free),即线程对其访问不需要加锁,因此对atomic_flag而言,也就不需要使用load、store等成员函数进行读写(或者重载操作符)。
实际上默认情况下,在C++11中的原子类型的变量在线程中总是保持着顺序执行的特性(非原子类型则没有必要,因为不需要在线程间进行同步
在C++11中,原子类型的成员函数(原子操作)总是保证了顺序一致性。
线程局部存储 thread local storage
简单地说,所谓线程局部存储变量,就是拥有线程生命期及线程可见性的变量。
通常情况下,线程会拥有自己的栈空间,但是堆空间、静态数据区(如果从可执行文件的角度来看,静态数据区对应的是可执行文件的data、bss段的数据,而从C/C++语言层面而言,则对应的是全局/静态变量)则是共享的。这样一来,全局、静态变量在这种多线程模型下就总是在线程间共享的。
C++11对TLS标准做出了一些统一的规定。与__thread修饰符类似,声明一个TLS变量的语法很简单,即通过thread_local修饰符声明变量即可。
cpp
int thread_local errcode;一旦声明一个变量为thread_local,其值将在线程开始时被初始化,而在线程结束时,该值也将不再有效。对于thread_local变量地址取值(&),也只可以获得当前线程中的TLS变量的地址值。
快速退出:quick_exit和at_quick_exit
首先我们可以看看terminate函数,terminate函数实际上是C++语言中异常处理的一部分(包含在<exception>头文件里)。而terminate函数在默认情况下,是去调用abort函数的
abort函数不会调用任何的析构函数(读者也许想到了,默认的terminate也是如此),默认情况下,它会向合乎POSIX标准的系统抛出一个信号(signal):SIGABRT。
exit函数会正常调用自动变量的析构函数,并且还会调用atexit注册的函数
而main或者exit函数调用会导致类的析构函数依次将这些零散的内存还给操作系统。
在C++11中,标准引入了quick_exit函数,该函数并不执行析构函数而只是使程序终止。
使用at_quick_exit注册的函数也可以在quick_exit的时候被调用
第7章 未改变思考方式而改变
nullptr、=default、=delete、lambda
指针空值 nullptr
指针空值 :从0到NULL,再到nullptr
一般情况下,NULL是一个宏定义。在传统的C头文件(stddef.h)里我们可以找到如下代码:
c
#undef NULL
#if defined(__cplusplus)
#define NULL 0
#else
#define NULL ((void *)0)
#endif在C++11标准中,nullptr是一个所谓“指针空值类型”的常量。指针空值类型被命名为nullptr_t
cpp
typedef decltype(nullptr) nullptr_t;在C++11标准中,nullptr类型数据所占用的内存空间大小跟void*相同的
cpp
sizeof(nullptr_t) == sizeof(void*)nullptr是一个编译时期的常量,它的名字是一个编译时期的关键字,能够为编译器所识别。而(void*)0只是一个强制转换表达式,其返回的也是一个void*指针类型。
C++11标准却规定用户不能获得nullptr的地址。其原因主要是因为nullptr被定义为一个右值常量,取其地址并没有意义。
默认函数的控制
在C++中声明自定义的类,编译器会默认帮助程序员生成一些他们未自定义的成员函数。
构造函数
拷贝构造函数
拷贝赋值函数(operator = )
移动构造函数
移动拷贝函数
析构函数
此外,C++编译器还会为以下这些自定义类型提供全局默认操作符函数:
- operator,
- operator &
- operator &&
- operator *
- operator ->
- operator ->*
- operator new
- operatpor delete
最常见的是声明了带参数的构造版本,则必须声明不带参数的版本以完成无参的变量初始化
C++11标准称“=default”修饰的函数为显式缺省(explicit defaulted)函数,而称“= delete”修饰的函数为删除(deleted)函数。
C++11引入显式缺省和显式删除是为了增强对类默认函数的控制,让程序员能够更加精细地控制默认版本的函数。
在C++11提案中,提案的作者并不建议用户将explicit关键字和显式删除合用
lambda 函数
在数理逻辑或计算机科学领域中,lambda则是被用来表示一种匿名函数,这种匿名函数代表了一种所谓的λ演算(lambda calculus)。
而通常情况下,lambda函数的语法定义如下:
[capture](parameters) mutable ->return-type{statement}[capture]:捕捉列表。捕捉列表总是出现在lambda函数的开始处。捕捉列表能够捕捉上下文中的变量以供lambda函数使用。
(parameters):参数列表。与普通函数的参数列表一致。如果不需要参数传递,则可以连同括号()一起省略。
mutable:mutable修饰符。默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。在使用该修饰符时,参数列表不可省略(即使参数为空)
->return-type:返回类型。用追踪返回类型形式声明函数的返回类型。出于方便,不需要返回值的时候也可以连同符号->一起省略。此外,在返回类型明确的情况下,也可以省略该部分,让编译器对返回类型进行推导
{statement}:函数体。除了可以使用参数之外,还可以使用所有捕获的变量
在lambda函数的定义中,参数列表和返还类型都是可选的部分,而捕捉列表和函数体都可能为空
捕捉列表描述了上下文中哪些的数据可以被lambda使用,以及使用方式(以值传递的方式或引用传递的方式)
捕捉列表有如下几种形式:
- [var]表示值传递方式捕捉变量var
- [=]表示值传递方式捕捉所有父作用域的变量(包括this)
- [&var] 表示引用传递捕捉变量var
- [&] 表示引用传递捕捉父作用域的变量(包括this)
- [this] 表示值传递方式捕捉当前的this指针
父作用域:enclosing scope,这里指的是包含lambda函数的语句块
值得注意的是,捕捉列表不允许变量重复传递.
lambda与仿函数
仿函数(functor,函数对象)简单地说,就是重定义了成员函数operator ()的一种自定义类型对象。
相比于函数,仿函数可以拥有初始状态,一般通过class定义私有成员,并在声明对象的时候对其进行初始化。私有成员的状态就成了仿函数的初始状态。
而事实上,仿函数是编译器实现lambda的一种方式。
或者更动听地说,lambda是仿函数的“语法甜点”
有的时候,我们在编译时发现lambda函数出现了错误,编译器会提示一些构造函数等相关信息。这显然是由于lambda的这种实现方式造成的。理解了这种实现,用户也就能够正确理解错误信息的由来。
具体地讲,按值方式传递捕捉列表和按引用方式传递捕捉列表效果是不一样的。对于按值方式传递的捕捉列表,其传递的值在lambda函数定义的时候就已经决定了。而按引用传递的捕捉列表变量,其传递的值则等于lambda函数调用时的值
在使用lambda函数的时候,如果需要捕捉的值成为lambda函数的常量,我们通常会使用按值传递的方式捕捉;反之,需要捕捉的值成为lambda函数运行时的变量(类似于参数的效果),则应该采用按引用方式进行捕捉。
从C++11标准的定义上可以发现,lambda的类型被定义为“闭包”(closure)的类[插图],而每个lambda表达式则会产生一个闭包类型的临时对象(右值)。
值得注意的是,程序员也可以通过decltype的方式来获得lambda函数的类型
C++11中,默认情况下lambda函数是一个const函数。按照规则,一个const的成员函数是不能在函数体中改变非静态成员变量的值的
lambda的捕捉列表中的变量都会成为等价仿函数的成员变量(如const_val_lambda中的成员val),而常量成员函数(如operator())中改变其值是不允许的,因而按值捕捉的变量在没有声明为mutable的lambda函数中,其值一旦被修改就会导致编译器报错。
现有C++11标准中的lambda等价的是有常量operator()的仿函数。
仿函数可以被定义以后在不同的作用域范围内取得初始值。这使得仿函数天生具有了跨作用域共享的特征。
第8章 融入实际应用
alignof、alignas、attribute、declspec、Unicode、locale、codecvt、raw string literal
对齐支持
在C++中,每个类型的数据除去长度等属性之外,都还有一项“被隐藏”属性,那就是对齐方式。
C++11标准定义的alignof函数来查看数据的对齐方式。
C++11在新标准中为了支持对齐,主要引入两个关键字:操作符alignof、对齐描述符(alignment-specifier)alignas。
如同sizeof操作符一样,alignof获得的也是一个与平台相关的值。
在C++11标准之前,我们也可以使用一些编译器的扩展来描述对齐方式,比如GNU格式的__attribute__((__aligned__(8)))就是一个广泛被接受的版本。
通用属性
扩展语法中比较常见的就是“属性”(attribute)。属性是对语言中的实体对象(比如函数、变量、类型等)附加一些的额外注解信息,其用来实现一些语言及非语言层面的功能,或是实现优化代码等的一种手段。
对于g++,属性是通过GNU的关键字__attribute__来声明的。
__attribute__ ((attribute-list))而在Windows平台上,我们会找到另外一种关键字__declspec。__declspec是微软用于指定存储类型的扩展属性关键字。
__declspec ( extended-decl-modifier )C++11的通用属性
[[ attribute-list ]]语法上,C++11的通用属性可以作用于类型、变量、名称、代码块等。
在现有C++11标准中,只预定义了两个通用属性,分别是[[ noreturn ]]和[[carries_dependency ]]。
[[ noreturn ]]是用于标识不会返回的函数的
不会返回和没有返回值的(void)函数的区别。没有返回值的void函数在调用完成后,调用者会接着执行函数后的代码;而不会返回的函数在被调用完成后,后续代码不会再被执行。
[[noreturn]]主要用于标识那些不会将控制流返回给原调用函数的函数,
通用属性[[ carries_dependency ]]则跟并行情况下的编译器优化有关。[[carries_dependency]]主要是为了解决弱内存模型平台上使用memory_order_consume内存顺序枚举问题。
Unicode支持
在Unicode中,每个字符占据一个码位(Code point)。Unicode字符集总共定义了1114 112个这样的码位,使用从0到10FFFF的十六进制数唯一地表示所有的字符。
常见的基于Unicode字符集的编码方式有UTF-8、UTF-16及UTF-32(一般人常常把UTF-16和Unicode混为一谈,在阅读各种资料的时候读者要注意区别)
内码实际就是字符在计算机存储单元中的二进制表示
C++11引入以下两种新的内置数据类型来存储不同编码长度的Unicode数据:
char16_t:用于存储UTF-16编码的Unicode数据
char32_t:用于存储UTF-32编码的Unicode数据
至于UTF-8编码的Unicode数据,C++11还是使用8字节宽度的char类型的数组来保存。
C++11还定义了一些常量字符串的前缀:
u8表示为UTF-8编码
u表示为UTF-16编码
U表示为UTF-32编码
通常情况下,按照C/C++的规则,连续在代码中声明多个字符串字面量,则编译器会自动将其连接起来。比如"a" "b"这样声明的方式与"ab"的声明方式毫无区别。
C++11中还规定了一些简明的方式,即在字符串中用'\u'加4个十六进制数编码的Unicode码位(UTF-16)来标识一个Unicode字符
cpp
#include <iostream>
using namespace std;
int main(){
char utf8[] = u8"\u4F60\u597D\u554A";
char16_t utf16[] = u"hello";
char32_t utf32[] = U"hello equals \u4F60\u597D\u554A";
cout << utf8 << endl;
cout << utf16 << endl;
cout << utf32 << endl;
char32_t u2[] = u"hello"; // Error
char u3[] = U"hello"; // Error
char16_t u4 = u8"hello"; // Error
}我们可以按照编写代码、编译、运行的顺序来看看它们对整个Unicode字符串输出的影响。
首先会影响Unicode正确性的过程是源文件的保存。
第二个会影响Unicode正确性的过程是编译。
第三个会影响Unicode正确性的过程是输出。
在C11中,程序员可以使用库中的一些新增的编码转换函数来完成各种Unicode编码间的转换。函数的原型如下:
c
size_t mbrtoc16(char16_t * pc16, const char * s, size_t n, mbstate_t * ps);
size_t c16rtomb(char * s, char16_t c16, mbstate _t * ps);
size_t mbrtoc32(char32_t * pc32, const char * s, size_t n, mbstate_t * ps);
size_t c32rtomb(char * s, char32_t c32, mbstate_t * ps);字母mb是multi-byte(这里指多字节字符串
c16和c32则是char16和char32的缩写,rt是convert(转换)的缩写
在中国使用简体中文并采用GB2312文字编码的locale则可以被表示为zh_CN.GB2312
原生字符串字面量(raw string literal)